

- 정규화(Normalization)란 인풋 데이터가 너무 들쭉날쭉하지 않도록 일정한 범위로 맞추는 작업임
- [필요성] 피처 간의 단위가 다를 경우, 단위가 큰 피처의 데이터가 쓸데없는 영향력을 가져 bias가 발생
ex) 한국 빅맥가격 : 5,500원 vs 미국 빅맥가격 : 5.3달러 → 단순 평균을 낸다고 해도 5,500에 편향된 값이 나옴
- [효험·효능] 인풋이 안정되면 아웃풋도 안정되어 학습이 수월해짐
: 아웃풋이 안정 → gradient가 안정 → 매끄러운 loss landscape → 빠른 descent
- [대표 기법] Standarzation, Min-max normalization → 인풋 범위가 0~1로 보정
- Standarzation : 값에서 평균를 빼고, 표준편차로 나눠줌

- Min-max normalization : 값에서 최소값을 뺀 뒤, 최대값과 최소값의 차이만큼 나눠줌

- 딥러닝 초기에는 처음 들어가는 인풋 데이터에 대해서만 정규화를 실행함
→ Internal Covariate Shift(내부 공변량 변화) 문제 발생
- 중간 레이어에서 값이 튀어 나가면 이를 인풋으로 받는 뒤쪽 레이어들이 폭주하는데 이걸 못 막음
- 이외에도 여러가지 문제점에 대한 대안으로 Batch Normalization이 제시됨
- 처음 넣을때 정규화하면 뭐해… 중간에서 급발진해버리면 답도 없어!
- 데이터 전체를 정규화하니까 계산량이 너무 많아!
- 정규화 과정이랑 학습 과정이 따로 노니까 모델 훈련이 좀 이상하게 되버려!
그러면 배치 단위로,
매 레이어마다 정규화를 하고,
정규화 과정도 학습 과정에 포함시켜!

- 근데, Batch Norm도 ①배치 크기가 작거나, ②배치 내의 데이터가 균질하지 않으면 한계가 있음..
- 이러한 한계는 문장 등과 같이 데이터들의 길이가 다른 “시퀀스 데이터”를 다룰 때 극명함

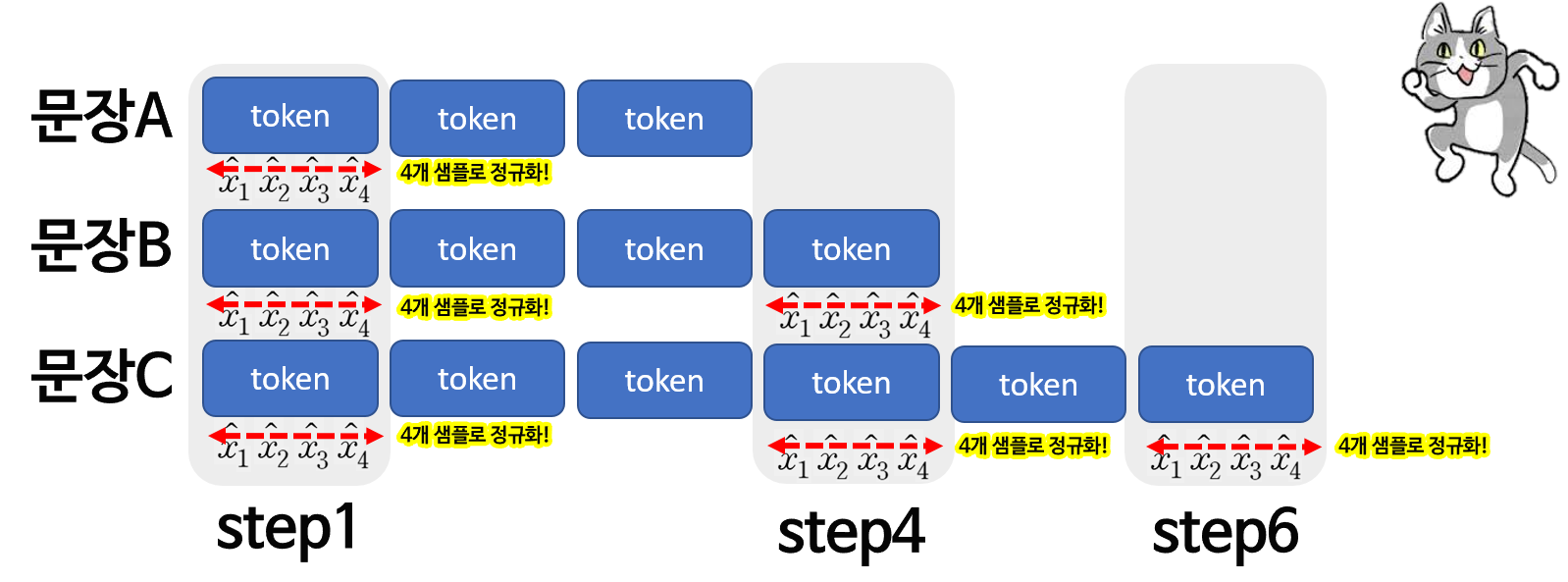
그러면, Batch Norm의 방식을 차용하되
각 샘플 내에서 피처를 기준으로 정규화를 하자!

- 더 이상 배치 크기를 신경쓰지 않아도 됨, 심지어 배치 크기가 1이어도 정규화 가능
- Batch Norm 보다 무조건 좋은건 아니지만, 적어도 텍스트 시퀀스 처리하는데 배치 크기를 신경안써도 되잖아? 좋았쓰!
'테크 > AI' 카테고리의 다른 글
| LLM 스터디 기초이론 자료 (0) | 2026.03.18 |
|---|---|
| Residual Connection (잔차 연결) (0) | 2026.01.19 |
| 딥러닝 기초용어 ④ (0) | 2025.12.28 |
| 딥러닝 기초용어 ③ (0) | 2025.12.28 |
| 딥러닝 기초용어 ② (0) | 2025.12.28 |



